When I first started writing this post I thought it was going to be about “reasoning”. However after some initial research it became clear that there are multiple interesting topics hiding behind the keyword: generalization, training vs inference compute and post training with reinforcement learning. Even the meaning of reasoning itself is ambiguous, is it about solving math and coding problems, or true system 2 thinking?
As we will see there has been impressive progress recently, especially in the domains of math, coding and science. While advcancements seems to generalize beyond these domains, I still think these models due not truly reason, as in the sense of system 2 cognition (another ill-defined term). However this seems surprisingly, at least to me, not to be necessary to achieve peak human performance in math and coding. The real world impact of these skills is a topic for another day, and something that frequently comes up at lunch discussions at work.
Basic Concepts and Notation
Before we start, let us quickly repeat some basic concepts and their notation. Readers familiar with the topic may skip this section.
- Sigmoid: \(\sigma : (-\infty,\infty) \longrightarrow (0,1)\), is defined as \(\sigma(x) := \frac{1}{1+\exp(-x)} = \frac{\exp(x)}{1+\exp(x)}\). It has the property that it maps any value to the open interval \((0,1)\), which is very useful if we want to extract a probability from a model.
- The plot looks as follows:
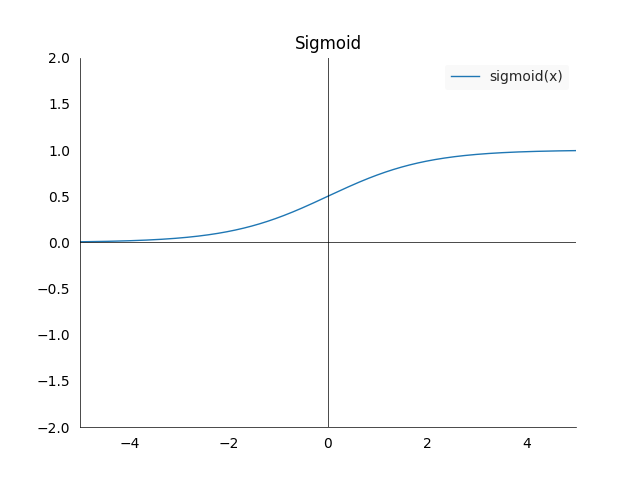
- Again three cases worth noting:
- The left limit is 0: \(\sigma(x)_{x \longrightarrow -\infty } = 0\)
- The right limit is 1: \(\sigma(x)_{x \longrightarrow \infty } = 1\)
- At zero we are in the middle of the limits: \(\sigma(0) = 0.5\)
- The derivative of the sigmoid is \(\frac{\partial \sigma(x)}{\partial x} = \sigma(x) (1-\sigma(x))\)
- The plot looks as follows:
Using recurrence to achieve weak to strong generalization
When doing research for this post I came accross this talk from Tom Goldstein about “Recurrance, a mechanism for weak-to-strong generalization -or- studying test time scaling without language models” at the Simons Institute. Even though this talk was given just last summer, it feels like from a different era. Mostly because the speaker identifies as “gpu poor” and the restrictions that follow from that. Nevertheless, the talk is a good introduction to some of the concepts we will see later on.
Here the speaker defines weak-to-strong generalization as the ability of the model to solver “harder” problems than those in the training set. This is a fundamental ability of humans that still separates us from the current models: we can learn to solve a few easy problems \(e^{i \pi} + 1 = 0\) and then logically extrapolate to much harder ones. All of this while using few samples, i.e. with much greater efficiency than current machine learning models.
The task they are using to test this is solving mazes, can you train on a 9x9 maze (left) and generalize to a 59x59 maze (right). Or even bigger ones?
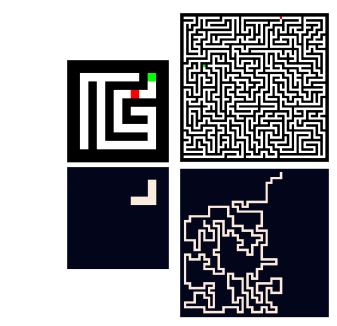
To solve this problem with classical machine learning, we could use a feed-forward neural (FFN) network that has five different layers (left). Or we can use a feature extractor with a recurrent layer in the middle and a solution predictor at the end (middle). This means that the weights in the middle three layers (A) are shared. In practice it was necessary to add some skip connections from the input to the repeated middle layers (right).

After training on 9x9 mazes we can then evaluate the different models on 13x13 mazes. Here is where things start to get interesting, with recurrent networks we can choose to spend more computation at test time. This is done by repeating the middle layers more often, in the graph below this is called iterations at test time. A FNN does not have that option, we can only do one forward pass through the whole network. For recurrent network this can help generalization, we can solve harder problems by spending more compute. This will be the overarching topic of this blog post.
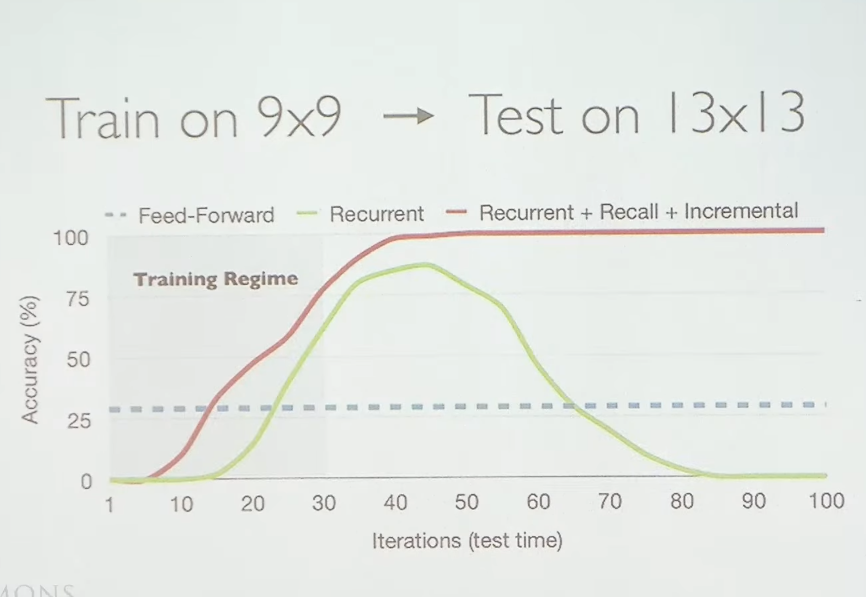
As the green and red plot line show, we have to be careful how the recurrent network is set up. Without skip connections and careful training the model can start “forgetting” the initial task, leading to a loss of performance for higher iterations (green line). Note that the recurrent model was only trained to deal with up to 30 iterations. This generalized to the previously mentioned 59x59 mazes and beyond. The authors show that this even works with a 801x801 maze when the model is run over 10’000 iterations.
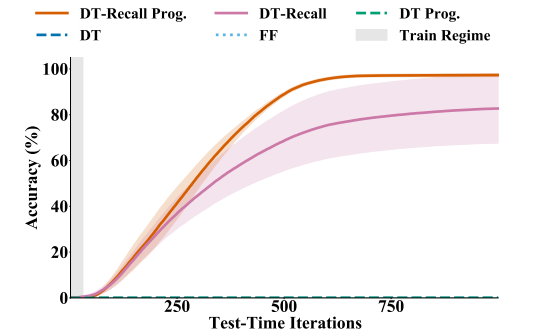
Youtube talk
Train on 9x9 maze and solve 800x800 maze. Works with 20000 iterations instead of 30 during train tim ewith RNN
Test time computation is for weak to strong generalization.
Having skip connections helps not forget. Using RNNs
Apply this to chess,
Sudoku is solved too.
But here we generalize in the same class of problems mostly. Easier task in same class chess/sudoku into harder task. But no generalization.
Transformers need to train with many positional embeddins. Take into account least significant at first because transformers are causal. So for 123 write 321
Training: Backward pass, do a progressive loss. Gets compute cost down for training recurrent transformer loss. Also called truncated backprop.
Testing time compute is actually the ovearching topic here?
He is not a huge fan of CoT (why?). CoT needs human generated data to see recurrence (this seems not obviously true anymore after DeepSeek).
Why doesn’t it fully work? Positional encoding is not precise enough. Abacus embeddings solve this issue to see what number belongs to what number in the sequence.
Easy to hard vs weak to strong generalization. Easy to hard is generalization outside of current problem space.
Boosting is in a weaker category than recurrent computation, or even CoT.
Recurrent models vs diffusion models. Diffusion models are trained to solve problems in one step, not like these models that are trained to do multi step problem solving.
What
Poker part, just scaling up, doing self play. Humans would talk long instead of act instantly for difficult problems.
Importance of search in poker. It would think for 30s towards the end of the game? Having think for 30s is same as scaling up 100000x.
2017 brains vs pokers won by 15bb/100 compared lost to 9bb/100 loss.
Why wasn’t search/planning considered in poker before? This is extra compute at test/inference time. Scaling test time compute makes inference/experiments much more expensive. Painful to run this. Incentives: it was all about winning the annual competition at 2 CPU cores for 2 seconds. Didn’t think about beating the best humans
People underestimated the impact of search, thought it would be 10x not 100’000x. Similar results in AlphaGo. Which used MCTS. Raw NN performance is below human performance, only becomes superhuman when you increase test time compute. How much would you need to scale up to get raw NN score to go to superhuman. Here again if you want to go from 3000 to 5200 elo you need 100’000x compute scale.
All of this applies to state of AI as well. We do pre-training for 100M+ and doing inference is costing pennies.
Is there a way to scale inference compute in LLMs?
Consensus is simplest way to scale up compute. Minerva paper. Get lift by sampling 10x or 100x but don’t get much more afterwards for majority voting. Not great retunrs for scaling inference compute. But there is often at least one answer that is correct.
OpenAI o1 compute scales differently, it goes from 20% to 80% in pass@1 accuarcy at AIME.
It works with CoT RL compute at it, so there is benefits from spending more compute on training and test time. Effective way to scale inference compute.
There are gains in O1 from many different areas. No big boost for english and literature. But more than STEM improves.
See research blog post from OpenAI “learning to reason with LLMs”.
Prompt with CoT, this increases quality results from prompt.
Optimize chain of thought, generate large scale CoT Wei et al NeuriPS 2022
Why does o1 work at all? Generator-Verifier gap. Easier to verify than generate a solution. When a generator-verification gap exists, we can spend more compute at infrence time to achieve better performance!
Models can do verification on their own? Know when they are making or not making progress??? (Seems vague).
Pre-training cost and data have become bottlenecks, not so for o1. Because we can scale up inference compute. And we have a lot of room to scale up inference compute.
Concern: Will increase cost and waiting time of queries. What inference time cost are we willing to pay for difficult problems like life-saving drugs?
AI can be much more than chatbots.
The bitter lesson by richard sutton (its a book/blog post?? TODO read). Two things that seem to scale arbitrarily well are search and learning.
He says: Don’t try to edge out current state of the art but try to think of techniques that scale with compute.
He says: Pre-training limitations are no longer a blocker, but we don’t know what other blockers exist or how far we can scale this.
Can we tell the model to tell how long to think? Can we make the model judge how long it should think about a specific task?
State of reasoning
Reasonign is poor direction for LLMs because they are not good at it
Why should LM reasoning be constrained to look like human reasoning?
CoT on LM is outputting intermediate steps, LMs are per token devices. No way to hold intermediate states, this is why CoT is reasonable.
LLMs have randomness built in, failures in reasoning are somewhat a feature of this.
o1 is maximizing the CoT approach
o1 is RL on verifiable outcomes.
-
Use rl on prompt and make many completions and grade the outcome. Helps RL policy to learn.
-
Loss function more flexible than IT, can go over same prompts many more times
post training flops exceed pre-training (for o1)
Reinforcement fine tuning reasearch program (from OpenAI)
Use repeated RL passes over data to encourage model to figure out more robust behaviors in domains.
Requires:
- Training data with explicit correct answers
- A grader for verifying outputs
- A model that can sometimes generate a correct solution (even with low probability)
So the RL signal can learn from this.
Key goal: Improve targeted skills reliably without degradation on other tasks. Big fear in industry, how is this exactly done? (Do some reesearch).
How to check the answer? Need to verify with LLMs or parsing. Need more than yes/no loss function for reasoning?
How would you grade code quality?
The unreasonable effectiveness of reasoning distillation: uwing deepseek R1 to beat openai o1
Conclusion
AAA
Final Thoughts
Some follow up questions and remarks for my future self or experts in this field:
- Similarly to LLMs, we seem to run out of training data as WebLI represents the entire (high quality) internet data, what else can be done? Generate more data with GenAI and use captioning for training smaller models?
- Are there any tasks that are not covered yet with the current training approaches?
- Could we use videos as another data source for further advances?
- A very 2025 take, can we apply RL to improve vision further? Explored to some extend already in 2023 by the Big Vision team.
References
A list of resources used to write this post, also useful for further reading:
- Learning to Reason with LLMs talk of Noam Brown at Simons Institute
- Title for XYZ
- Understanding Reasoning LLMs blog post about reasoning in LLMs. Strong focus on DeepSeek.
Comments
I would be happy to hear about any mistakes or inconsistencies in my post. Other suggestions are of course also welcome. You can either write a comment below or find my email address on the about page.